本文介绍算法库中常用的算法,其实大部分函数的使用建议大家直接去看微软的文档
格式
首先要引入算法库#include<algorithm>。算法库的函数参数基本都是一对迭代器表示的容器范围,最后一个参数为一个自定义的函数,大多有缺省值可以省略。如果有返回值都是以迭代器的形式返回,而不是元素或者元素的引用。
大家先记住这个基本格式,后面认识函数名应该就可以推断如何使用了。还有一些其他的格式变体,会在下面的过程中慢慢认识。
拷贝
一个非常简单的函数,copy接受三个迭代器作为参数,将一个范围的数据复制到另一个范围,我们要保证目标容器能够容纳这些数据。返回值为输出迭代器接收的元素的后一个位置,一般不使用返回值。简单使用如下,1
2
3vector<int>A{1,2,3,4,5};
vector<int>B(5);
copy(A.begin(),A.end(),B.begin());
copy的一个变体copy_n,_n变体的范围表示不是一对迭代器,而是起始迭代器和元素个数。下面的代码是从A中复制两个元素到B1
2
3vector<int>A{1,2,3,4,5};
vector<int>B(5);
copy_n(A.begin(),2,B.begin());
copy还有一种输入输出的用法,效率上有没有提升不知道,但是看起来很优雅。下面的代码是从cin中复制5个int到A中,然后将A中的元素复制到cout,并以空格分隔。1
2
3vector<int>A(5);
copy_n(istream_iterator<int>(cin),5,A.begin());
copy(A.begin(),A.end(),ostream_iterator<int>(cout," "));
再以copy为例讲一种常用变体,_if变体。这种变体多接受一个函数作为参数,用于判断元素是否符合条件,copy_if就是复制范围中符合条件的元素。下面的代码是复制A中的偶数到B,并输出1
2
3
4vector<int>A{1,2,3,4,5};
vector<int>B(5);
auto it=copy_if(A.begin(),A.end(),B.begin(),[](int a){return (a%2)==0;});
copy(B.begin(),it,ostream_iterator<int>(cout," "));
计数
count接受一对迭代器表示的范围,和一个要统计个数的元素,返回指定范围中指定元素的个数,使用如下,1
2vector<int>A{1,3,3,4,5};
cout<<count(A.begin(),A.end(),3)<<endl;
它更常用的变体是count_if,第三个参数为条件,返回符合条件的元素个数,下面示例是返回偶数个数,1
2vector<int>A{1,2,3,4,5};
cout<<count_if(A.begin(),A.end(),[](int a){return (a%2)==0;})<<endl;
查找
find接受一对迭代器表示的范围和要查找的值作为参数,(可选)判断相等的函数,返回在容器中找到第一个相等的元素的迭代器,太常规了没什么好说的,1
2vector<int>A{1,2,3,4,5};
auto it=find(A.begin(),A.end(),2);
它最常用的版本是find_if,查找第一个满足条件的元素,下面以查找第一个偶数为例1
2vector<int>A{1,2,3,4,5};
auto it=find(A.begin(),A.end(),[](int a){return (a%2)==0;});
最大最小值、第n大/小值
max和min用于返回两个元素中的最大值或最小值大家应该都知道了,如果是容器中的最大值最小值应该使用max_element和min_element,参数为一对迭代器表示的范围。1
2
3vector<int>A{1,2,3,4,5};
auto a=max_element(A.begin(),A.end());
auto b=max_element(A.begin(),A.end());
还有一个第n大/小值,nth_element,区别在于第三个参数为n,第四个参数指定排序方式,小于是第n小,大于是第n大,1
2
3vector<int>A{1,2,3,4,5};
auto a=nth_element(A.begin(),A.end(),less<int>());
auto b=nth_element(A.begin(),A.end(),greater<int>());
排序
算法库中最常用的排序是sort,这种排序的实现是快速排序,是不稳定排序,稳定排序的话是stable_sort两者的参数格式完全一样,时间复杂度也都为O(n \log n),但是sort的常数比stable_sort小,一般情况下sort会快一点。
sort的参数是一对迭代器和比较函数(默认是小于,升序),原址排序。
如果问为什么小于是升序,一种比较好理解的方法就是,这个比较函数就是相邻元素之间满足的条件,即相邻元素的连接方式,就像下面这样1
2小于:1<2<3<4<5,这样是升序
大于:5>4>3>2>1,这样是降序
下面代码演示了升序和降序怎么写,还有如何传入自定义比较函数。1
2
3
4
5
6
7vector<int>A{1,3,5,4,2};
sort(A.begin(),A.end());
copy(A.begin(),A.end(),ostream_iterator<int>(cout," "));
cout<<endl;
sort(A.begin(),A.end(),[](int a,int b){return a>b;});
copy(A.begin(),A.end(),ostream_iterator<int>(cout," "));
cout<<endl;
二分查找
二分查找相信大家应该都写过,应该都知道这个东西的使用条件,只能在排序好的数组上使用。算法库中的二分查找叫binary_search,参数格式和find差不多,只是最后一个参数不是判断相等的函数,是排序的函数(默认小于),例如用小于比较排序得到的的升序数组就用小于,要跟排序使用的函数相同。懒得写大于了,使用标准库中的大于greater。1
2
3vector<int>A{1,2,3,4,5};
sort(A.begin(),A.end(),greater<int>());
auto it=binary_search(A.begin(),A.end(),2,greater<int>());
跟二分查找一个系列的,还有两个也是只能在排序数组上使用的函数,lower_bound和upper_bound。这两个函数参数和binary_search一样,唯一的区别就是是否包含指定的元素,大家可以看下图自己理解一下,大概就是lower_bound会包含指定元素,upper_bound为指定元素右边第一个元素。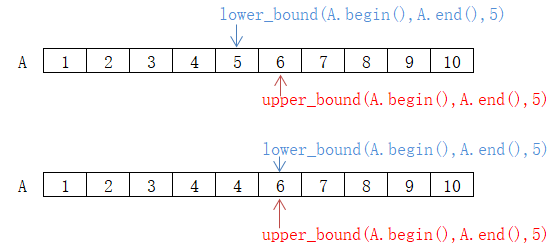
总结
这篇文章我觉得到这里就可以了,最常用的函数就这些,更多的其实是让大家认识算法库的函数的格式,看完上面的示例大家应该可以根据功能猜参数了,剩下的应该可以看文档认识函数了,最重要的还是要知道这些函数怎么使用。